Our MongoDB integration is still in beta. Some features, such as column-level lineage, are not yet supported. Please contact us if you need assistance.
Configure user in MongoDB
To connect to MongoDB, create a user with read-only access to all databases you plan to diff.Configure in Datafold
| Field name | Description |
|---|---|
| Connection name | The name you’d like to assign to this connection in Datafold. |
| Host | The hostname for your MongoDB instance. For MongoDB Atlas, use your cluster hostname (e.g., cluster0.mongodb.net). |
| Port | MongoDB endpoint port (default value is 27017). Not required for MongoDB Atlas connections. |
| User ID | User ID (e.g., DATAFOLD). |
| Password | Password for the user provided above. |
| Database | Database to connect to. |
| Authentication database | Database name associated with the user credentials (e.g., admin). |
MongoDB Atlas clusters (using
*.mongodb.net domains) automatically use the SRV protocol for connection, which performs server discovery and load balancing. Other MongoDB deployments connect directly to the specified host and port.Diff your data
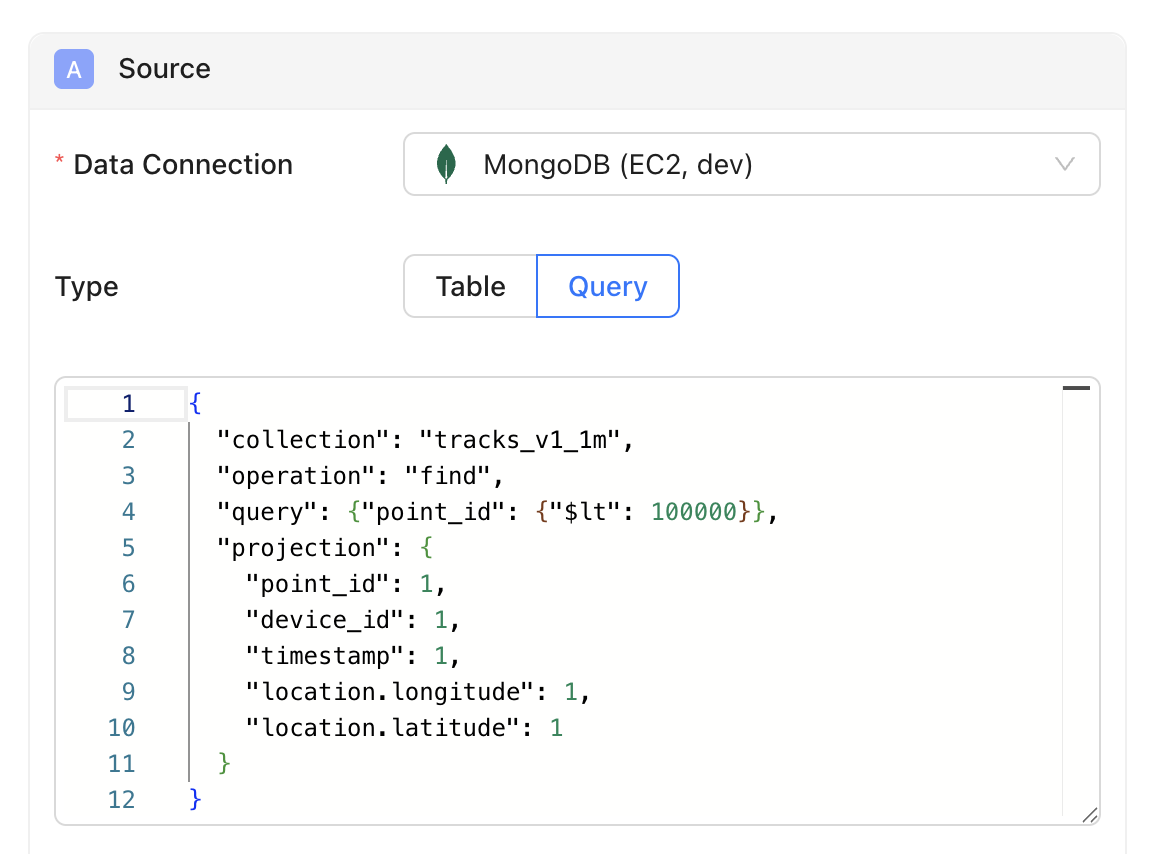
- Create a new data diff.
- Select your MongoDB data connection.
- Select Query diff. Only query diffs are supported for MongoDB. Table diffs are not available.
- Write a native MongoDB query using JSON format. All queries must include a
collectionname and anoperationtype (eitherfindoraggregate).
Query structure
All MongoDB queries use a JSON wrapper with the following structure:Supported operations
We support two MongoDB operations:find and aggregate.
Primary keys are required for data diffs. Your query results must include the primary key field (typically
_id in MongoDB) to run a diff. The find operation is the typical and recommended approach for data diffs, as it preserves document identity. The aggregate operation may not be suitable for diffs if the pipeline transforms or groups data in a way that loses the primary key.Find operation
Usefind to query documents with filters, projections, and sorting. This is the typical operation for data diffs:
collection(required): The collection name.operation(required): Must be"find".query(optional): Filter criteria using MongoDB query operators (default:{}).projection(optional): Fields to include or exclude. Important: Always include the primary key field (typically_id) in your projection for data diffs to work.sort(optional): Sort specification as an array of[field, direction]pairs.limit(optional): Maximum number of documents to return.skip(optional): Number of documents to skip for pagination.
Aggregate operation
Useaggregate to run aggregation pipelines with multiple stages. Note: Aggregate queries may not be suitable for data diffs if the pipeline groups or transforms data in a way that removes the primary key:
collection(required): The collection name.operation(required): Must be"aggregate".pipeline(required): Array of aggregation stages (e.g.,$match,$group,$project,$lookup,$sort,$limit). Important: Ensure your pipeline preserves the primary key field if you need to run a data diff.
Examples
Find with nested fields:- Configure the rest of your diff and run it.
Datafold automatically limits data transfer to 10GB per query based on calculated record size to ensure optimal performance. This limit is applied automatically based on sampling your data.