INFOVPC deployments are an Enterprise feature. Please email sales@datafold.com to enable your account.
Create a Domain Name (optional)
You can either choose to use your domain (for example,datafold.domain.tld) or to use a Datafold managed domain (for example, yourcompany.dedicated.datafold.com).
Customer Managed Domain Name
Create a DNS A-record for the domain where Datafold will be hosted. For the DNS record, there are two options:- Public-facing: When the domain is publicly available, we will provide an SSL certificate for the endpoint.
- Internal: It is also possible to have Datafold disconnected from the internet. This would require an internal DNS (for example, AWS Route 53) record that points to the Datafold instance. It is possible to provide your own certificate for setting up the SSL connection.
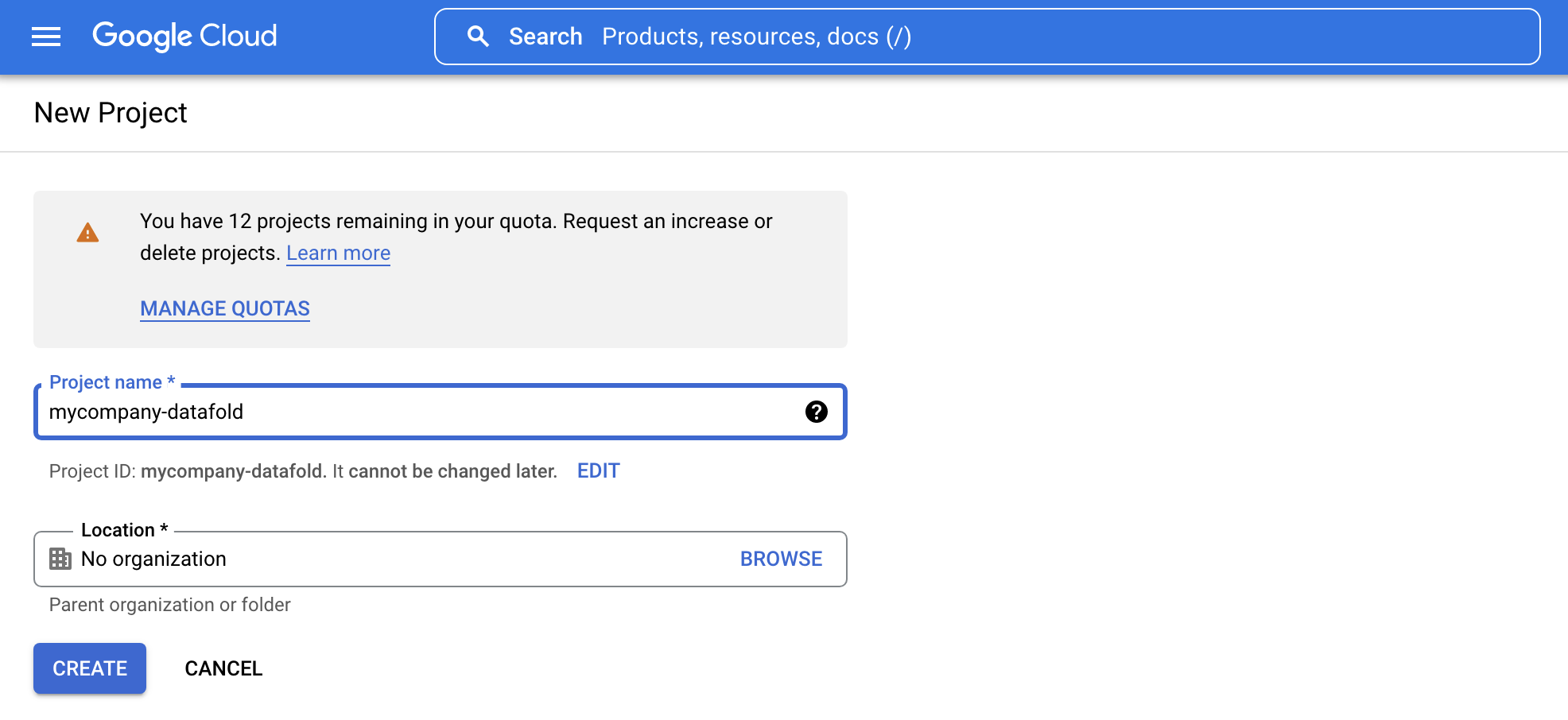
Create a New Project
For isolation reasons, it is best practice to create a new project within your GCP organization. Please call it something likeyourcompany-datafold to make it easy to identify:
Set IAM Permissions
Navigate to the IAM tab in the sidebar and click Grant Access to invite Datafold to the project.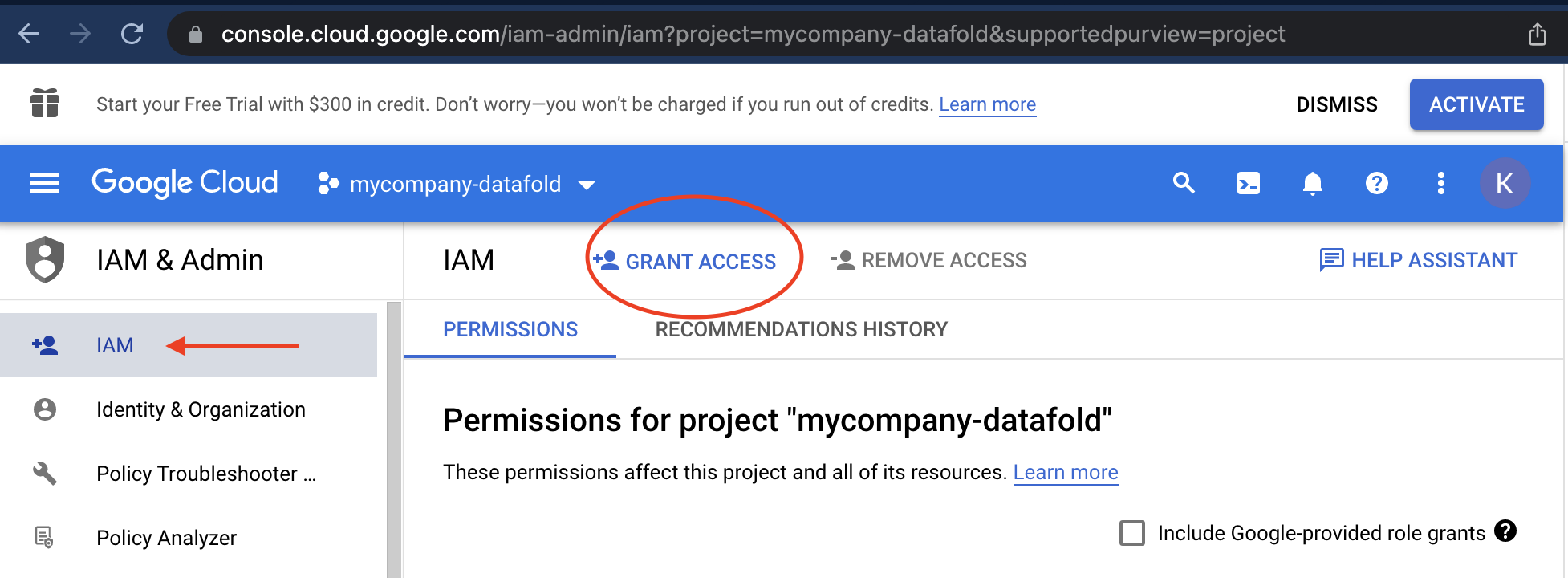
- Assign them as an owner of your project.
- Assign the extended set of Minimal IAM Permissions.
Required APIs
The following GCP APIs need to be additionally enabled to run Datafold: The following GCP APIs we use are already turned on by default when you created the project: Once the access has been granted, make sure to notify Datafold so we can initiate the deployment.Minimal IAM Permissions
Because we work in a Project dedicated to Datafold, there is no direct access to your resources unless explicitly configured (e.g., VPC Peering). The following IAM roles are required to update and maintain the infrastructure.Datafold Google Cloud infrastructure details
This document provides detailed information about the Google Cloud infrastructure components deployed by the Datafold Terraform module, explaining the architectural decisions and operational considerations for each component.Persistent disks
The Datafold application requires 3 persistent disks for storage, each deployed as encrypted Google Compute Engine persistent disks in the primary availability zone. This also means that pods cannot be deployed outside the availability zone of these disks, because the nodes wouldn’t be able to attach them. ClickHouse data disk serves as the analytical database storage for Datafold. ClickHouse is a columnar database that excels at analytical queries. The default 40GB allocation usually provides sufficient space for typical deployments, but it can be scaled up based on data volume requirements. The pd-balanced disk type provides consistent performance for analytical workloads with automatically managed IOPS and throughput. ClickHouse logs disk stores ClickHouse’s internal logs and temporary data. The separate logs disk prevents log data from consuming IOPS and I/O performance from actual data storage. Redis data disk provides persistent storage for Redis, which handles task distribution and distributed locks in the Datafold application. Redis is memory-first but benefits from persistence for data durability across restarts. The 50GB default size accommodates typical caching needs while remaining cost-effective. All persistent disks are encrypted by default using Google-managed encryption keys, ensuring data security at rest. The disks are deployed in the first availability zone to minimize latency and simplify backup strategies.Load balancer
The load balancer serves as the primary entry point for all external traffic to the Datafold application. The module offers 2 deployment strategies, each with different operational characteristics and trade-offs. External Load Balancer Deployment (the default approach) creates a Google Cloud Load Balancer through Terraform. This approach provides centralized control over load balancer configuration and integrates well with existing Google Cloud infrastructure. The load balancer automatically handles SSL termination, health checks, and traffic distribution across Kubernetes pods. This method is ideal for organizations that prefer infrastructure-as-code management and want consistent load balancer configurations across environments. Kubernetes-Managed Load Balancer deployment setsdeploy_lb = false and relies on the Google Cloud Load Balancer Controller
running within the GKE cluster. This approach leverages Kubernetes-native load balancer management, allowing for
dynamic scaling and easier integration with Kubernetes ingress resources. The controller automatically provisions and manages load balancers based on Kubernetes service definitions, which can be more flexible for applications that need to scale load balancer resources dynamically.
For external load balancers deployed through Kubernetes, the infrastructure developer needs to create SSL policies and
Cloud Armor policies separately and attach them to the load balancer through annotations. Internal load balancers cannot
have SSL policies or Cloud Armor applied. Our Helm charts support various deployment types including internal/external
load balancers with uploaded certificates or certificates stored in Kubernetes secrets.
The choice between these approaches often depends on operational preferences and existing infrastructure patterns.
External deployment provides more predictable resource management, while Kubernetes-managed deployment offers greater flexibility for dynamic workloads.
Security A firewall rule shared between the load balancer and the GKE nodes allows traffic to reach only the GKE nodes and nothing else.
The load balancer allows traffic to land directly into the GKE private subnet.
Certificate The certificate can be pre-created by the customer and then attached, or a Google-managed SSL certificate can be created on the fly.
The application will not function without HTTPS, so a certificate is mandatory. After the certificate is created either
manually or through this repository, it must be validated by the DNS administrator by adding an A record. This puts the
certificate in “ACTIVE” state. The certificate cannot be found when it’s still provisioning.
GKE cluster
The Google Kubernetes Engine (GKE) cluster forms the compute foundation for the Datafold application, providing a managed Kubernetes environment optimized for Google Cloud infrastructure. Network Architecture The entire cluster is deployed into private subnets. This means the data plane is not reachable from the Internet except through the load balancer. A Cloud NAT allows the cluster to reach the internet (egress traffic) for downloading pod images, optionally sending Datadog logs and metrics, and retrieving the version to apply to the cluster from our portal. The control plane is accessible via a private endpoint using a Private Service Connect setup from, for example, a VPN VPC elsewhere. This is a private+public endpoint, so the control plane can also be made accessible through the Internet, but then the appropriate CIDR restrictions should be put in place. For a typical dedicated cloud deployment of Datafold, only around 100 IPs are actively used. This assumes 3 e2-standard-8 instances where one node runs ClickHouse+Redis, another node runs the application, and a third node may be put in place when version rollovers occur. Even so, we recommend a subnet of size /22 (1,022 IPs) at minimum, which leaves enough headroom for pod scaling, version rollovers, and future growth. You can always apply a different CIDR per subnet if needed. By default, the repository creates a VPC and subnets, but by specifying the VPC ID of an already existing VPC, the cluster and load balancer get deployed into existing network infrastructure. This is important for some customers where they deploy a different architecture without Cloud NAT, firewall options that check egress, and other DLP controls. Add-ons The cluster includes essential add-ons like CoreDNS for service discovery, the VPC-native networking for networking, and the GCE persistent disk CSI driver for persistent volume management. These components are automatically updated and maintained by Google, reducing operational overhead. Node Management supports up to three managed node pools, allowing for workload-specific resource allocation. Each node pool can be configured with different machine types, enabling cost optimization and performance tuning for different application components. The cluster autoscaler automatically adjusts node count based on resource demands, ensuring efficient resource utilization while maintaining application availability. One typical way to deploy is to let the application pods go on a wider range of nodes, and set up tolerations and labels on the second node pool, which are then selected by both Redis and ClickHouse. This is because Redis and ClickHouse have restrictions on the zone they must be present in because of their disks, and ClickHouse is a bit more CPU intensive. This method optimizes CPU performance for the Datafold application. Security Features include several critical security configurations:- Workload Identity is enabled and configured with the project’s workload pool, providing fine-grained IAM permissions to Kubernetes pods without requiring Google Cloud credentials in container images
- Shielded nodes are enabled with secure boot and integrity monitoring for enhanced node security
- Binary authorization is configured with project singleton policy enforcement to ensure only authorized container images can be deployed
- Network policy is enabled using Calico for pod-to-pod communication control
- Private nodes are enabled, ensuring all node traffic goes through the VPC network