What is CI?
Continuous Integration (or CI) is a process for building and testing changes to your code before deploying to production. This ensures early detection of potential issues and improves the quality of code deployment.Datafold in CI
Datafold provides two complementary CI capabilities:- Data Diffs — Automatically compare production and staging data to catch unintended data changes at the row and column level.
- AI Code Reviews — Get LLM-powered analysis of your SQL and pipeline code to catch logic errors, anti-patterns, and best practice violations.
Data Diffs in CI
For Data Diffs to work in CI, you need to add a step that builds in your CI process (e.g., GitHub).Prerequisite: Building staging data in CIIf you’re using dbt, you’ll need to add a dbt build step to your CI pipeline first. This can be done through either dbt Cloud or dbt Core.For other orchestrators like Airflow, follow this guide to build staging data in CI, or contact us for custom recommendations based on your infrastructure.
Creating production and staging data
When Datafold is integrated into your CI, it automatically detects and highlights value-level differences between production data and staging data. These summarized Data Diff results are written directly in your pull request (PR) as a comment. From the comment, you can access the Datafold App to explore value-level differences, understand the impact on downstream BI tools, and other context-rich information about the impact of your PR code changes.Production data
Production data refers to the data that your organization depends on for daily operations, such as powering dashboards and BI tools. Your orchestrator (e.g., dbt, Airflow) is responsible for running SQL code that builds and maintains this data in your warehouse. If you use dbt, we’ll assume that you have a production job in either dbt Cloud or dbt Core that builds or updates your dbt models in the warehouse on a schedule. Or, you might have a scheduled job in Airflow or another orchestrator that builds production data on a regular basis.Staging data
For Datafold to run Data Diffs in CI, you need a step in your CI process that builds staging data (a version of your data in a dedicated schema) using the code in your PR/MR branch. Datafold will compares this staging data against your production data when diffing.- Setting up dbt in CI for dbt Cloud users
- Setting up dbt in CI for dbt Core users
- Building staging data in CI using Airflow
Comparing production and staging data
Once you have a job in CI that builds staging data, you’re ready to get started with Datafold in CI! By comparing production and staging data, Datafold ensures that any code changes are thoroughly validated before being merged, helping to prevent data issues from reaching production. We’ll walk through the setup steps in more detail in the Getting Started section.Datafold in CI for dbt users
While Datafold can be added to CI no matter what orchestrator you use, it’s worth detailing exactly how this works with dbt, a popular and opinionated tool for which we have specific recommendations.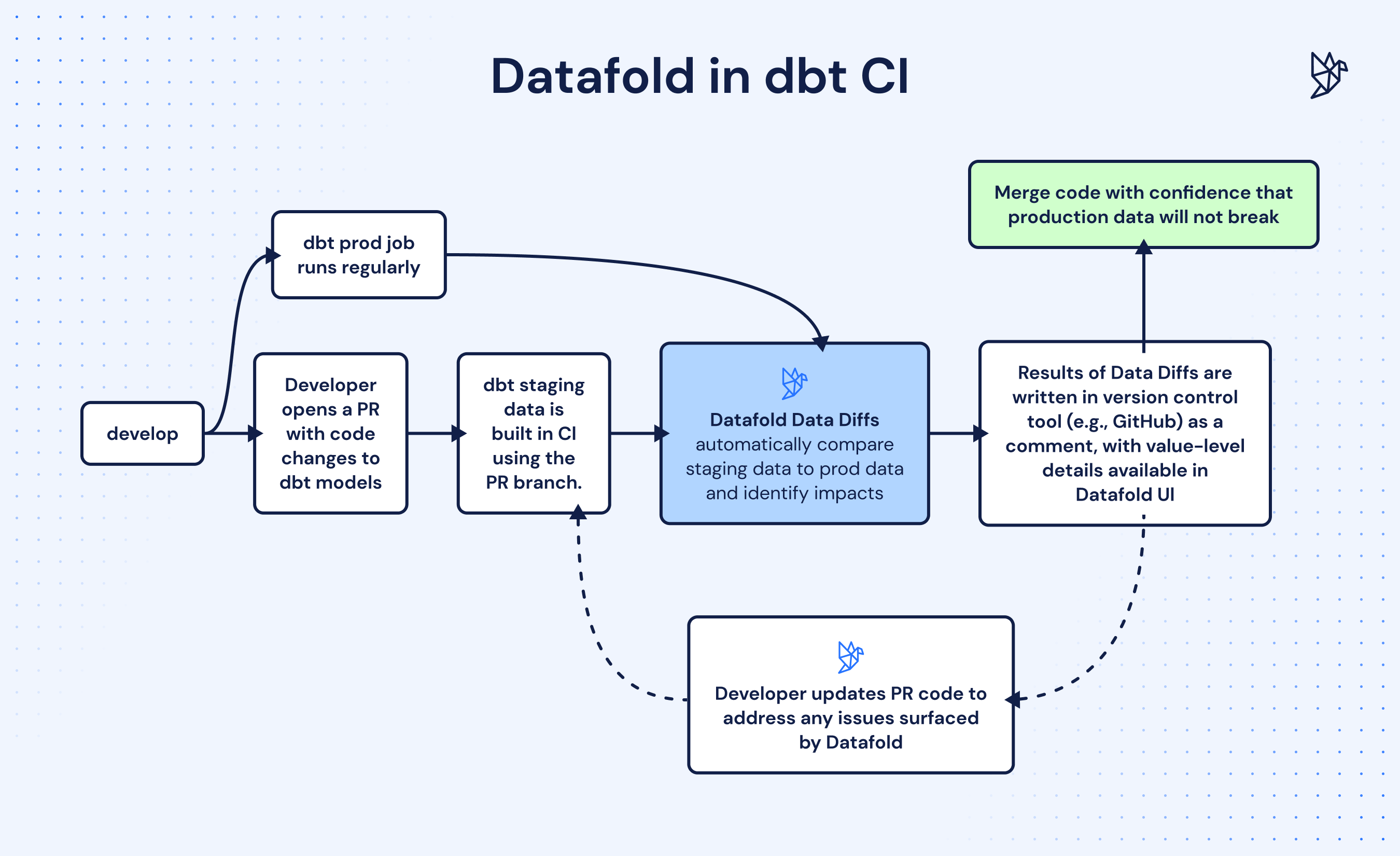
1
Submit dbt Project Manifests
Two versions of your dbt project’s
manifest.json are submitted to Datafold, representing the state of the production code and the PR/MR code.- For dbt Cloud users, this submission happens automatically.
- dbt Core users need to add steps in their CI configuration (e.g., Circle CI, GitHub Actions, or GitLab) to submit the artifacts.
2
Identify Code Differences
Datafold compares the two versions of the
manifest.json to identify differences in the code.3
Run Data Diffs
Datafold queries your data warehouse to run Data Diffs on the modified dbt models. It also identifies downstream assets (e.g., BI tools, reverse ETL pipelines) that might be impacted by the changes.
- Datafold can diff dbt models that are materialized as both tables and views.
- If your dbt project has many downstream dependencies, you can use Slim Diff or other configuration options to manage scale, ensuring critical models are prioritized.
4
Summarize Data Diffs in Pull Request
The results of the Data Diffs are summarized in a comment on your pull request (e.g., in GitHub). You can click the comment to view more detailed information in the Datafold application.