PREREQUISITES
- Create a Data Connection Integration where your dbt project data is built.
- Create a Code Repository Integration where your dbt project code is stored.
Getting started
To add Datafold to your continuous integration (CI) pipeline using dbt Core, follow these steps:1. Create a dbt Core integration.
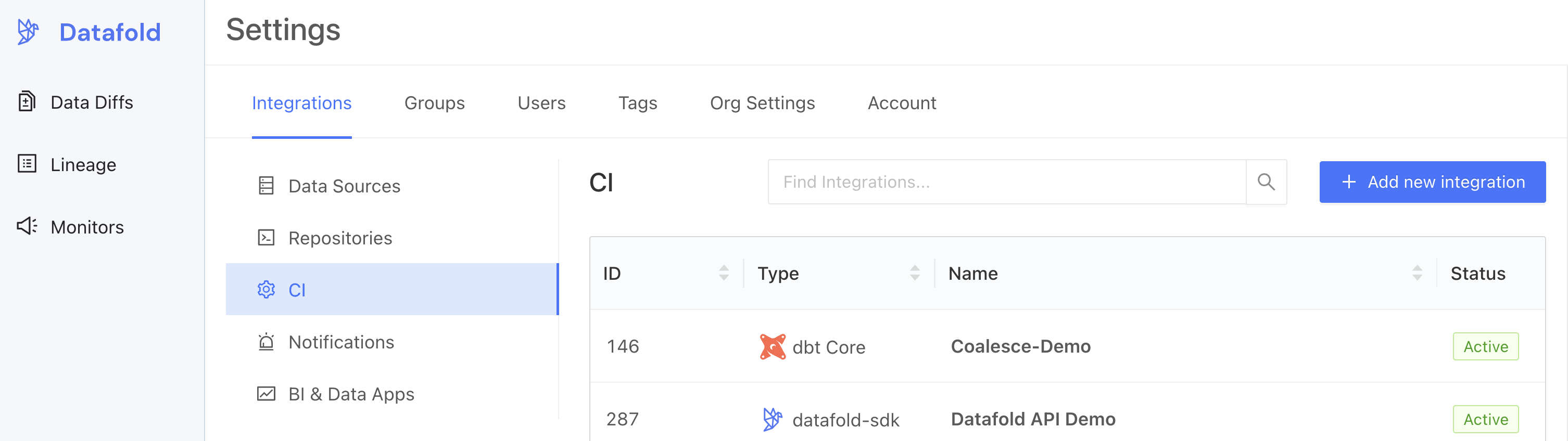
2. Set up the dbt Core integration.
Complete the configuration by specifying the following fields:Basic settings
Advanced settings: Configuration
Advanced settings: Sampling
Sampling allows you to compare large datasets more efficiently by checking only a randomly selected subset of the data rather than every row. By analyzing a smaller but statistically meaningful sample, Datafold can quickly estimate differences without the overhead of a full dataset comparison. To learn more about how sampling can result in a speedup of 2x to 20x or more, see our best practices on sampling.3. Obtain an Datafold API Key and CI config ID.
After saving the settings in step 2, scroll down and generate a new Datafold API Key and obtain the CI config ID.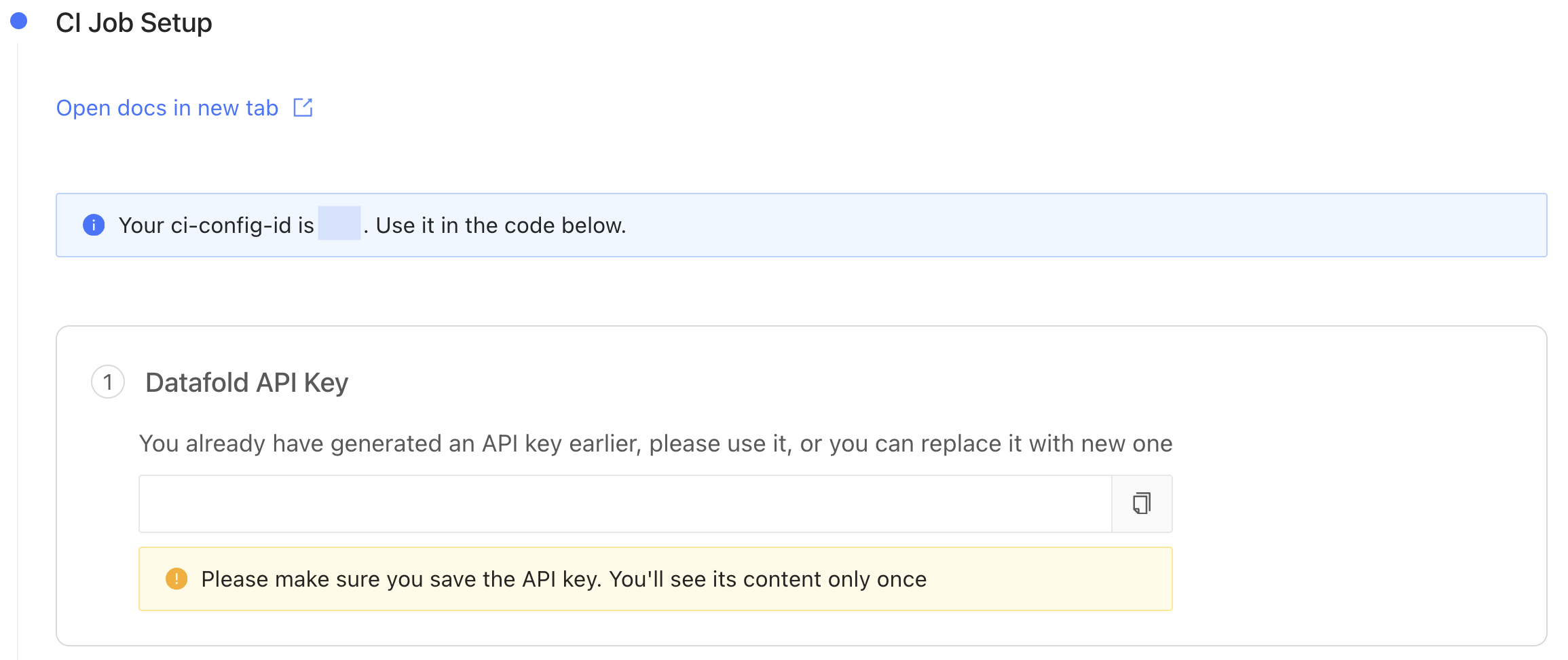
4. Configure your CI script(s) with the Datafold SDK.
Using the Datafold SDK, configure your CI script(s) to upload dbtmanifest.json files.
The datafold dbt upload command takes this general form and arguments:
manifest.json files in 2 scenarios:
- On merges to main. These
manifest.jsonfiles represent the state of the dbt project on the base/production branch from which PRs are created. - On updates to PRs. These
manifest.jsonfiles represent the state of the dbt project on the PR branch.
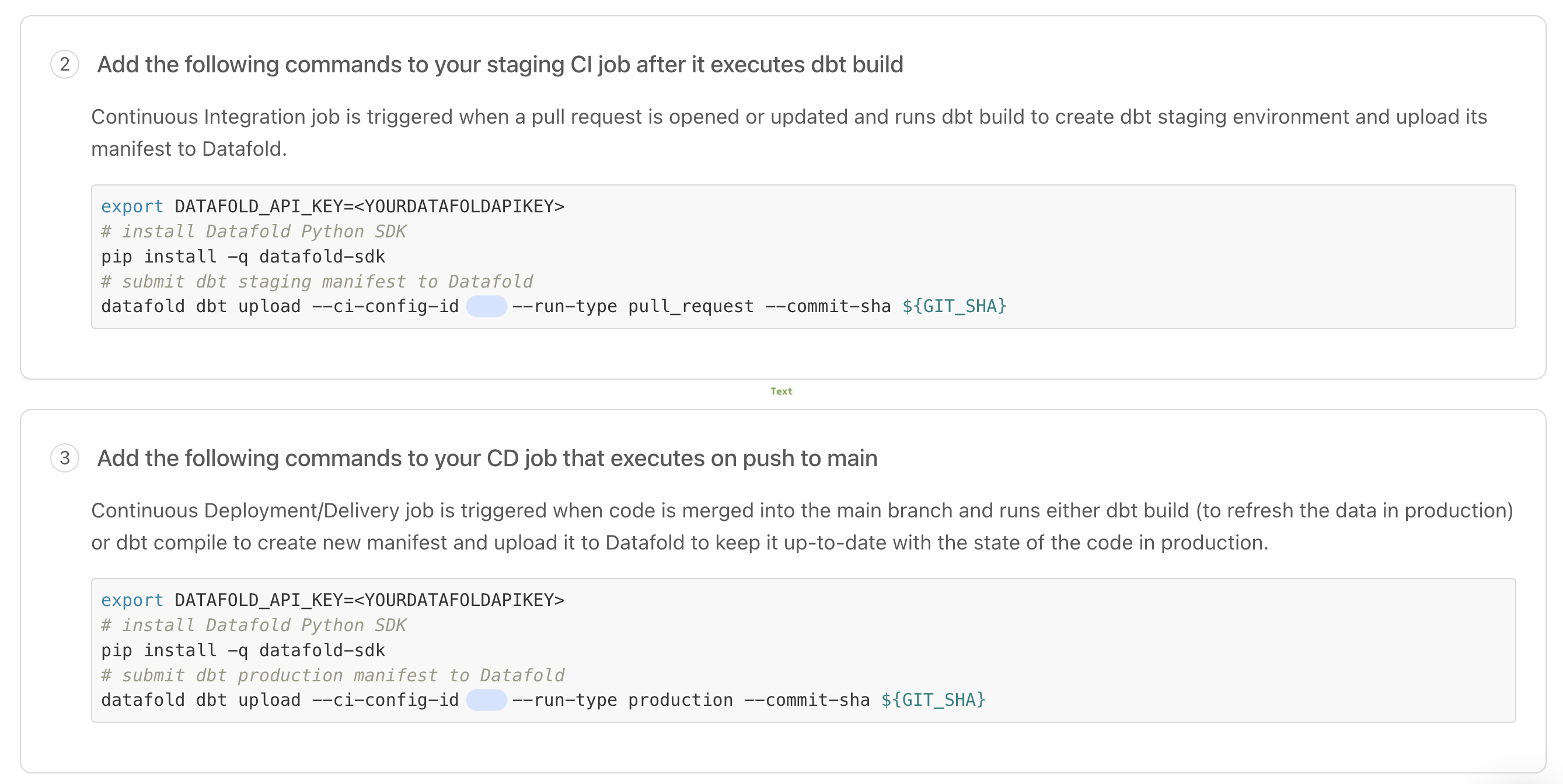
manifest.json files, Datafold determines which dbt models to diff in a CI run.
Implementation details vary depending on which CI tool you use. Please review these instructions and examples to help you configure updates to your organization’s CI scripts.
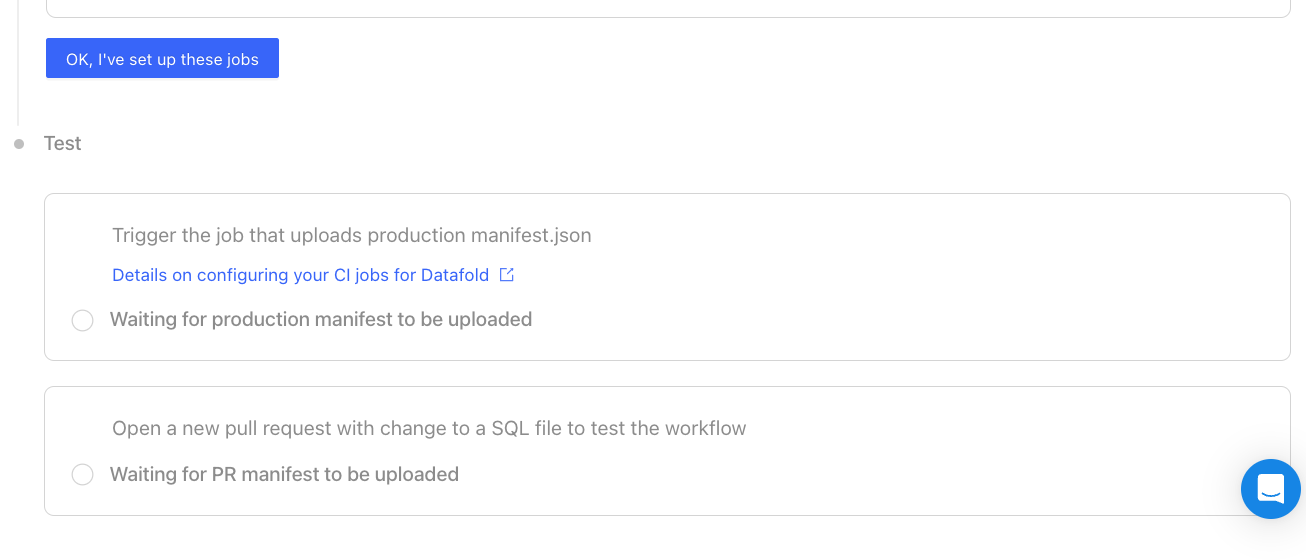
5. Test your dbt Core integration.
After updating your CI scripts, trigger jobs that will uploadmanifest.json files represent the base/production state.
Then, open a new pull request with changes to a SQL file to trigger a CI run.
CI implementation tools
We’ve created guides and templates for three popular CI tools. To add Datafold to your CI tool, adddatafold dbt upload steps in two CI jobs:
- Upload Production Artifacts: A CI job that build a production
manifest.json. This can be either your Production Job or a special Artifacts Job that runs on merge to main (explained below). - Upload Pull Request Artifacts: A CI job that builds a PR
manifest.json.
manifest.json files, enabling us to run data diffs comparing production data to dev data.
- GitHub Actions
- CircleCI
- GitLab CI
Upload Production ArtifactsAdd the Artifacts JobIf your existing Production Job runs on a schedule and not on merges to the base branch, create a dedicated job that runs on merges to the base branch which generates and uploads a Pull Request ArtifactsInclude the Store Datafold API KeySave the API key as
datafold dbt upload step to either your Production Job or an Artifacts Job.Production JobIf your dbt prod job kicks off on merges to the base branch, add a datafold dbt upload step after the dbt build step.manifest.json file to Datafold.datafold dbt upload step in your CI job that builds PR data.DATAFOLD_API_KEY in your GitHub repository settings.CI for dbt multi-projects
When setting up CI for dbt multi-projects, each project should have its own dedicated CI integration to ensure that changes are validated independently.CI for dbt multi-projects within a monorepo
When managing multiple dbt projects within a monorepo (a single repository), it’s essential to configure individual Datafold CI integrations for each project to ensure proper isolation. This approach prevents unintended triggering of CI processes for projects unrelated to the changes made. Here’s the recommended approach for setting it up in Datafold: 1. Create separate CI integrations: Create separate CI integrations within Datafold, one for each dbt project within the monorepo. Each integration should be configured to reference the same GitHub repository. 2. Configure file filters: For each CI integration, define file filters to specify which files should trigger the CI run. These filters prevent CI runs from being initiated when files from other projects in the monorepo are updated. 3. Test and validate: Before deployment, test each CI integration to validate that it triggers only when changes occur within its designated dbt project. Verify that modifications to files in one project do not inadvertently initiate CI processes for unrelated projects in the monorepo.Advanced configurations
Skip Datafold in CI
To skip the Datafold step in CI, include the stringdatafold-skip-ci in the last commit message.