Why do I need Datafold if I already have dbt tests?
Why do I need Datafold if I already have dbt tests?
You need Datafold in addition to dbt tests because while dbt tests are effective for validating specific assertions about your data, they can’t catch all issues, particularly unknown unknowns. Datafold identifies value-level differences between staging and production datasets, which dbt tests might miss.Unlike dbt tests, which require manual configuration and maintenance, Datafold automates this process, ensuring continuous and comprehensive data quality validation without additional overhead. This is all embedded within Datafold’s unified platform that offers end-to-end data quality testing with our Column-level Lineage and Data Monitors.Hence, we recommend combining dbt tests with Datafold to achieve complete test coverage that addresses both known and unknown data quality issues, providing a robust safeguard against potential data integrity problems in your CI pipeline.
What do I need to implement Datafold for dbt?
What do I need to implement Datafold for dbt?
For dbt Core users, create an integration in Datafold, specify the necessary settings, obtain a Datafold API Key and CI config ID, and configure your CI scripts with the Datafold SDK to upload manifest.json files. Our detailed setup guide can be found here.For dbt Cloud users, set up dbt Cloud CI to run Pull Request jobs and create an Artifacts Job that generates production manifest.json on merges to main/master. Obtain your dbt Cloud access URL and a Service Token, then create a dbt Cloud integration in Datafold using these credentials. Configure the integration with your repository, data connection, primary key tag, and relevant jobs. Our detailed setup guide can be found here.
We currently have a dbt Cloud Slim CI job. Does Datafold work with the custom PR schema that dbt Cloud creates?
We currently have a dbt Cloud Slim CI job. Does Datafold work with the custom PR schema that dbt Cloud creates?
Yes, Datafold is fully compatible with the custom PR schema created by dbt Cloud for Slim CI jobs.
How can I optimize diff performance in dbt?
How can I optimize diff performance in dbt?
We outline effective strategies for efficient and scalable data diffing in our performance and scalability guide.For dbt-specific diff performance, you can exclude certain columns or tables from data diffs in your CI/CD pipeline by adjusting the Advanced settings in your Datafold CI/CD configuration. This helps reduce processing load by focusing diffs on only the most relevant columns.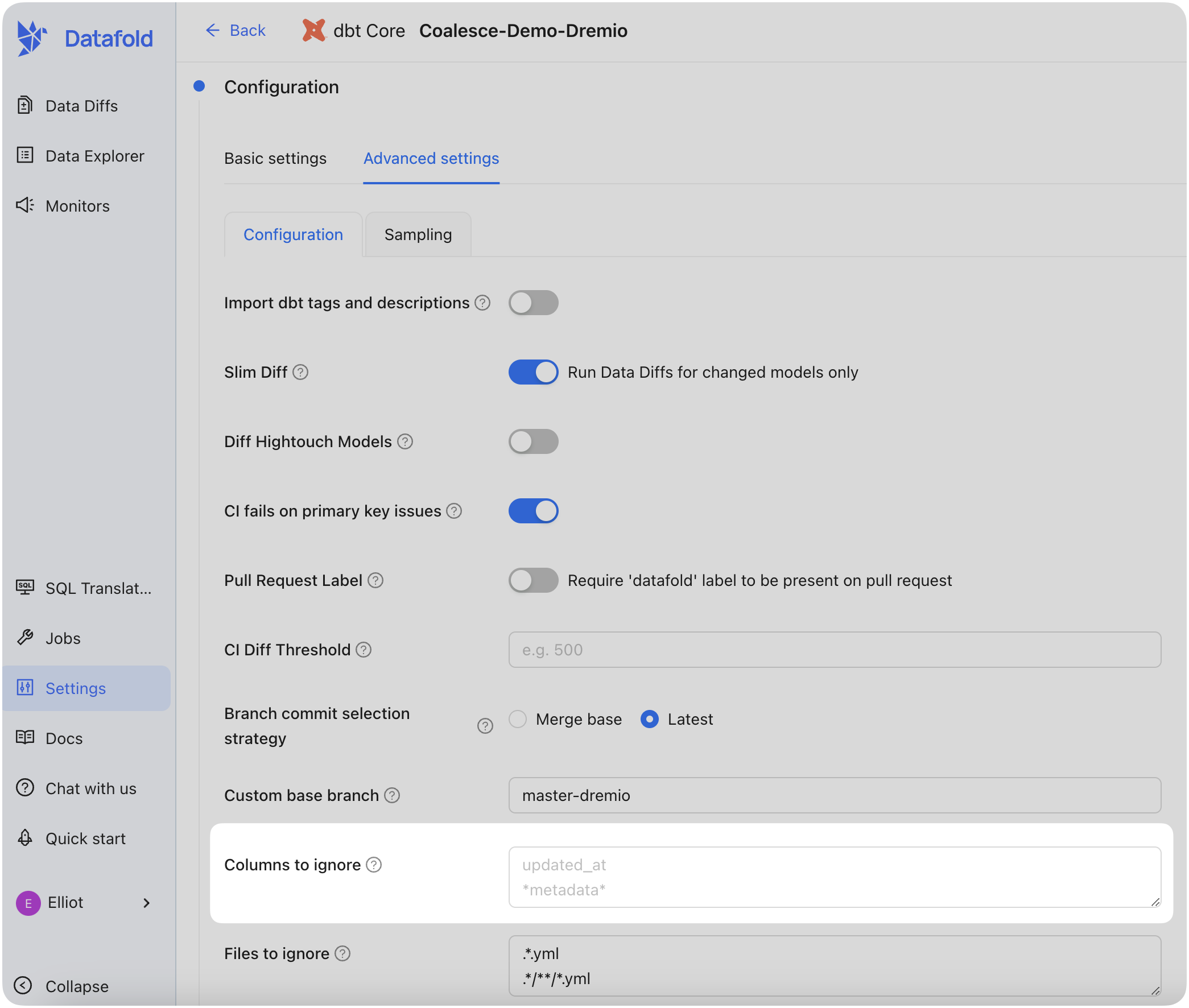
Can I run Data Diffs before opening a PR?
Can I run Data Diffs before opening a PR?
Some teams want to show Data Diff results in their tickets before creating a pull request. This speeds up code reviews as developers can QA code changes before requesting a PR review.You can trigger a Data Diff by first creating a draft PR and then running the following command via the CLI:This command runs
dbt locally and then triggers a Data Diff, allowing you to preview data changes without pushing to Git.To automate this process of kicking off a Data Diff before pushing code to git, we recommend creating a GitHub Actions job for draft PRs. For example: