Enable sampling
Sampling can be helpful when diffing between extremely large datasets as it can result in a speedup of 2x to 20x or more. The extent of the speedup depends on various factors, including the scale of the data, instance sizes, and the number of data columns. The following table illustrates the speedup achieved with sampling in different databases, varying instance sizes, and different numbers of data columns:
When sampling is enabled, Datafold compares a randomly chosen subset of the data. Sampling is the tradeoff between the diff detail and time/cost of the diffing process. For most use cases, sampling does not reduce the informational value of data diffs as it still provides the magnitude and specific examples of differences (e.g., if 10% of sampled data show discrepancies, it suggests a similar proportion of differences across the entire dataset).
Handling data type differences
Datafold automatically manages data type differences during cross-database diffing. For example, when comparing decimals with different precisions (e.g.,DECIMAL(38,15) in SQL Server and DECIMAL(38,19) in Snowflake), Datafold automatically casts values to a common precision before comparison, flagging any differences appropriately. Similarly, for timestamps with different precisions (e.g., milliseconds in SQL Server and nanoseconds in Snowflake), Datafold adjusts the precision as needed for accurate comparisons, simplifying the diffing process.
Optimizing OLTP databases: indexing best practices
When working with row-oriented transactional databases like PostgreSQL, optimizing the database structure is crucial for efficient data diffing, especially for large tables. Here are some best practices to consider:- Create indexes on key columns:
- It’s essential to create indexes on the columns that will be compared, particularly the primary key columns defined in the data diffs.
-
Example: If your data diff involves primary key columns
colAandcolB, ensure that indexes are created for these specific columns. - Use separate indexes for primary key columns:
- Indexes for primary key columns should be distinct and start with these columns, not as subsets of other indexes. Having a dedicated primary key index is critical for efficient diffing.
-
Example: Consider a primary key consisting of
colAandcolB. Ensure that the index is structured in the same order, like (colA,colB), to align with the primary key. An index with an order of (colB,colA) is strongly discouraged due to the impact on performance. -
Example: If the index is defined as (
colA,colB,colC) and the primary key is a combination ofcolAandcolB, then when setting up the diff operation, ensure that the primary key is specified ascolA,colB.If the order is reversed ascolB,colA, the diffing process won’t be able to fully utilize indexing, potentially leading to slower performance. - Leverage compound indexes:
- Compound indexes, which involve multiple columns, can significantly improve query performance during data diffs as they efficiently handle complex queries and filtering.
-
Example: An index defined as (
colA,colB,colC) can be beneficial for diffing operations involving these columns, as it aligns with the order of columns in the primary key.
Handling high percentage of differences
Data diff is optimized to perform best when the percent of different rows/values is relatively low, to support common data validation scenarios like data replication and migration. While the tool strives to maximize the database’s computational power and minimize data transfer, in extreme cases with very high difference percentages (up to 100%), it may result in transferring every row over the network, which is considerably slower. In order to avoid long-running diffs, we recommend the following:- Start with diffing primary keys only to identify row-level completeness first, before diffing all or more columns.
- Set an egress limit to automatically stop the diffing process after set number of rows are downloaded over the network.
- Set a per-column diff limit to stop finding differences for each column after a set number are found. This is especially useful in data reconciliation where identifying a large number of discrepancies (e.g., large percentage of missing/different rows) early on indicates that a detailed row-by-row diff may not be required, thereby saving time and computational resources.
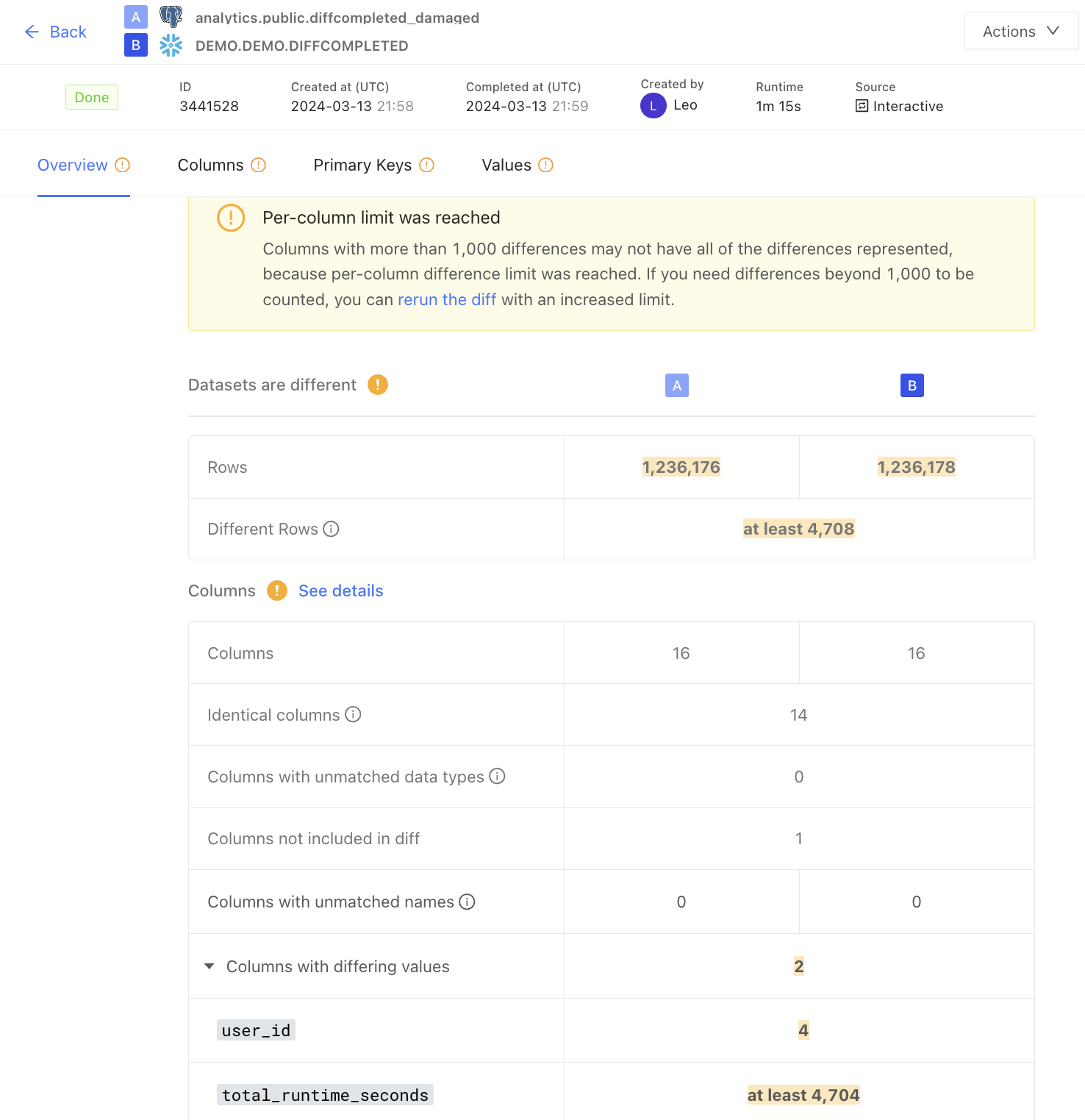
user_id, but “at least 4,704 differences” were found in total_runtime_seconds. user_id has a number of differences below the per-column diff limit, and so we state the exact number. On the other hand, total_runtime_seconds has a number of differences greater than the per-column diff limit, so we state “at least.” Note that due to our algorithm’s approach, we often find significantly more differences than the limit before diffing is halted, and in that scenario, we report the value that was found, while stating that more differences may exist.
Executing queries in parallel
Increase the number of concurrent connections to the database in Datafold. This enables queries to be executed in parallel, significantly accelerating the diff process. Navigate to the Settings option in the left sidebar menu of Datafold. Adjust the max connections setting to increase the number of concurrent connections Datafold can establish with your data. Note that the maximum allowable value for concurrent connections is 64.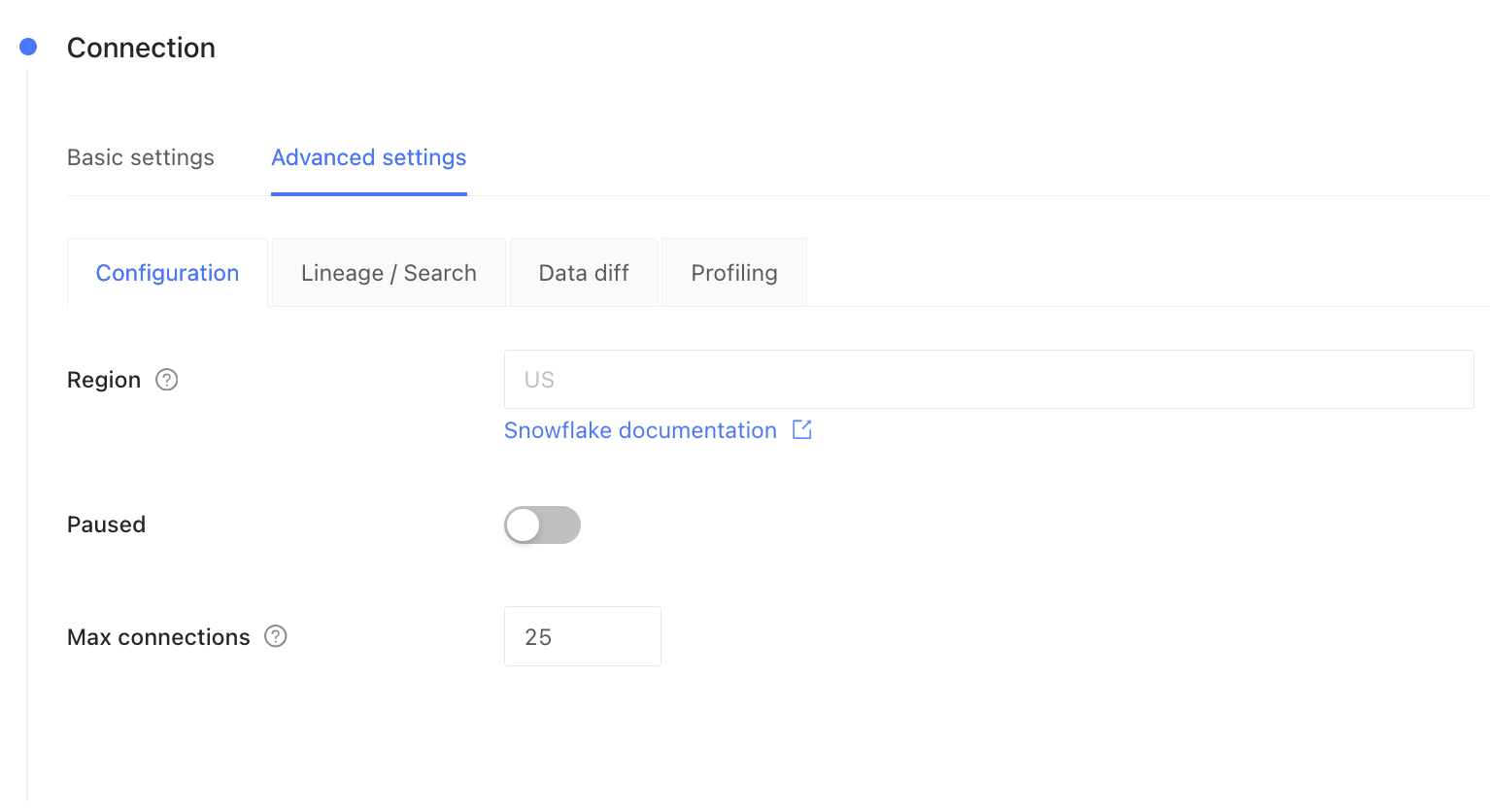
Optimize column selection
The number of columns included in the diff directly impacts its speed: selecting fewer columns typically results in faster execution. To optimize performance, refine your column selection based on your specific use case:- Comprehensive verification: For in-depth analysis, include all columns in the diff. This method is the most thorough, suitable for exhaustive data reviews, albeit time-intensive for wide tables.
- Minimal verification: Consider verifying only the primary key and
updated_atcolumns. This is efficient and sufficient if you need to validate rows have not been added or removed, and that updates are current between databases, but do not need to check for value-level differences between rows with common primary keys. - Presence verification: If your main concern is just the presence of data (whether data exists or has been removed), such as identifying missing hard deletes, verifying only the primary key column can be sufficient.
- Hybrid verification: Focus on key columns that are most critical to your operations or data integrity, such as monetary values in an
amountcolumn, while omitting large serialized or less critical columns likejson_settings.
Managing primary key distribution
Significant gaps in the primary key column can decrease diff efficiency (e.g., 10s of millions of continuous rows missing). Datafold will execute queries for non-existent row ranges, which can slow down the data diff.Handling different primary key types
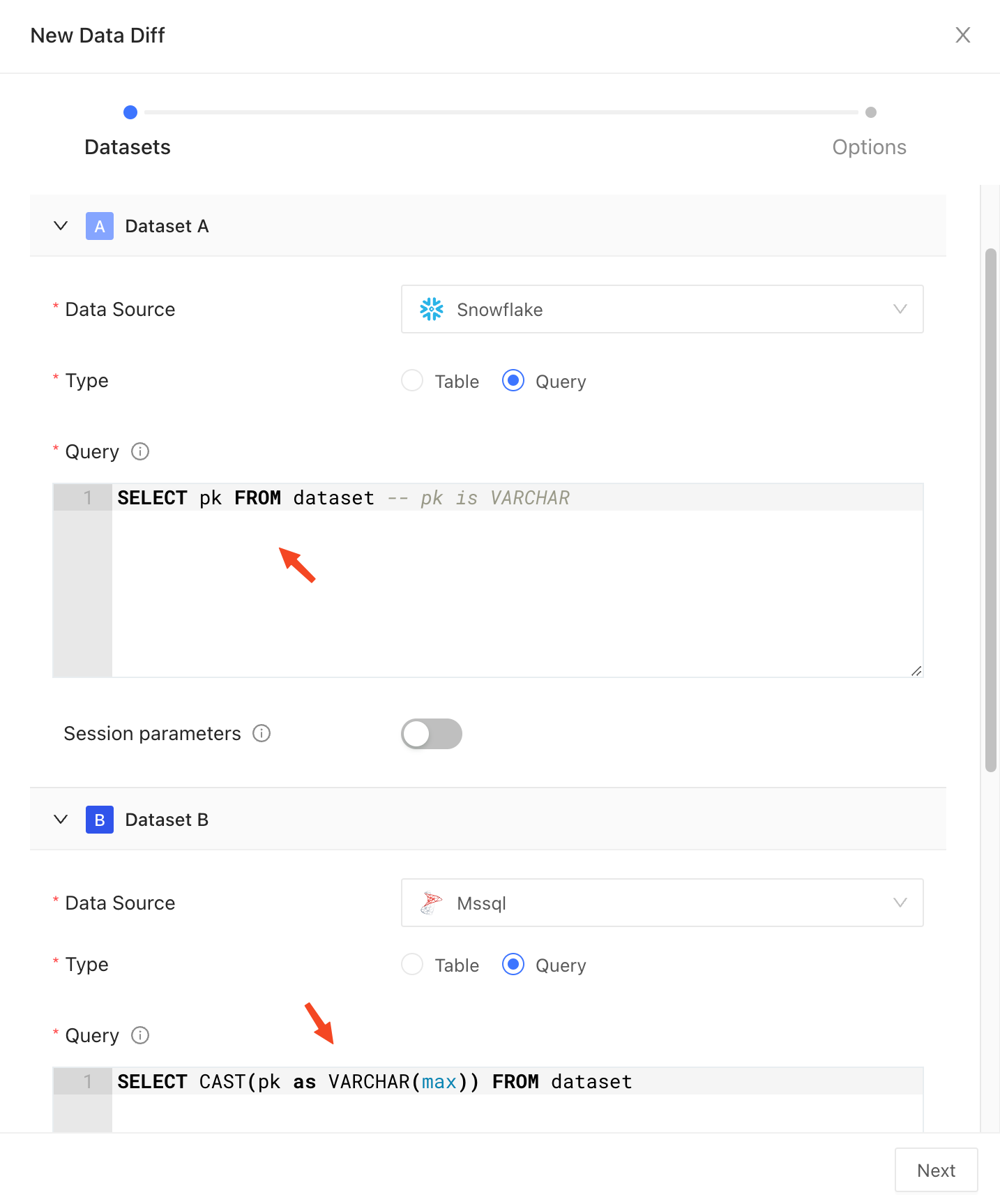
As a general rule, primary keys should be of the same (or similar) type in both datasets for diffing to work properly. Comparing primary keys of different types (e.g.,INT vs VARCHAR) will result in a type mismatch error. You can still diff such datasets by casting the primary key column to the same type in both datasets explicitly.
Indexes on the primary key typically cannot be utilized when the primary key is cast to a different type. This may result in slower diffing performance. Consider creating a separate index, such as expression index in PostgreSQL, to improve performance.