1. Create a repository integration
Integrate your code repository using the appropriate integration.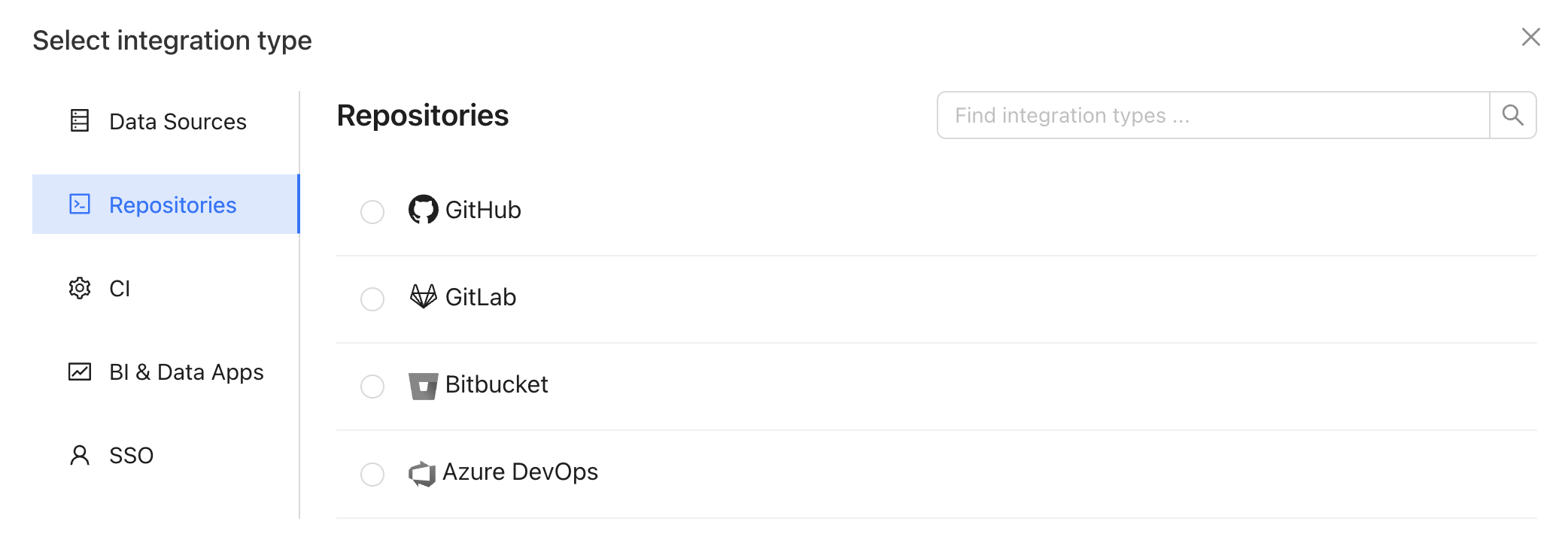
2. Create an API integration
In the Datafold app, create an API integration.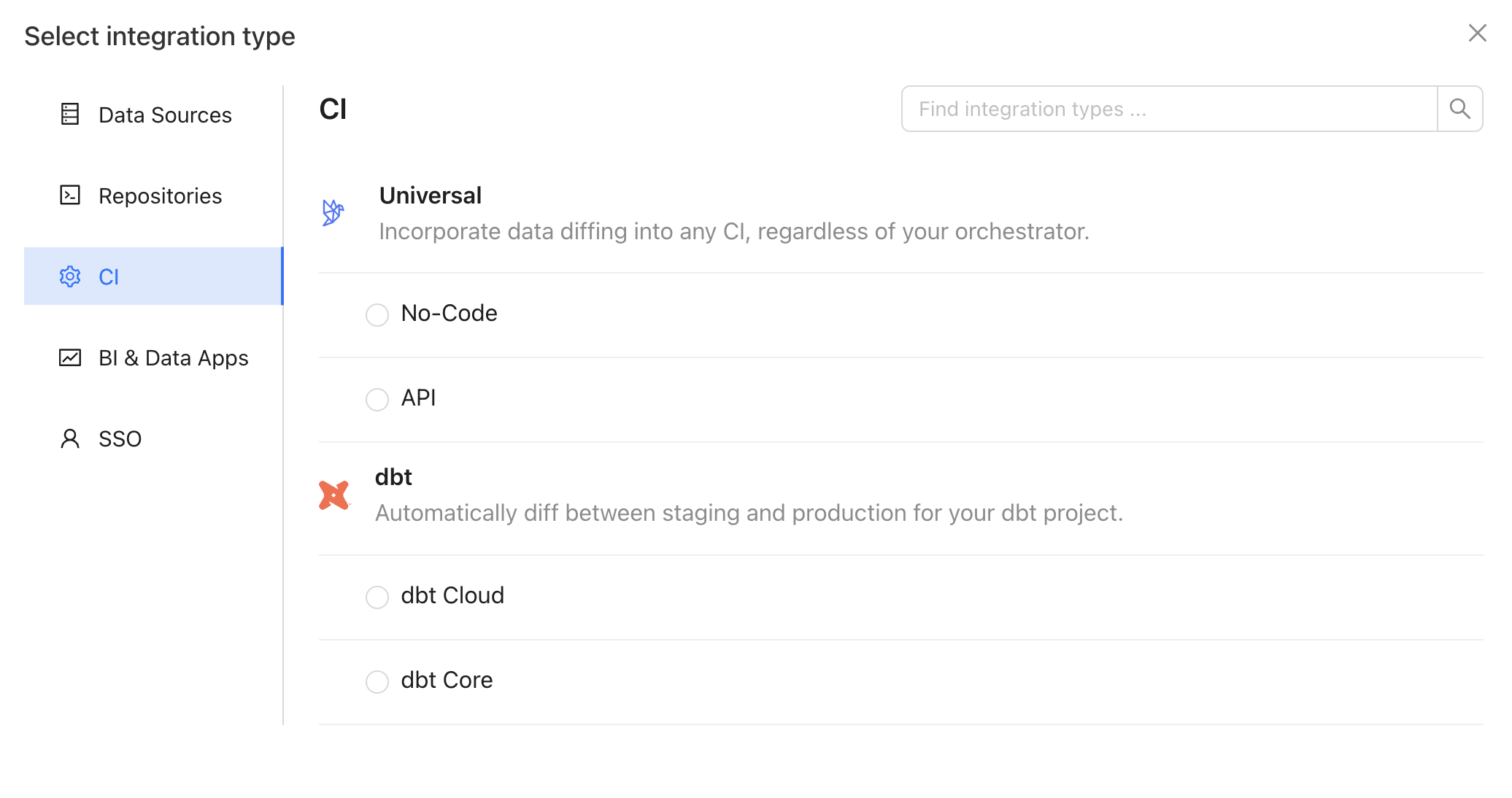
3. Set up the API integration
Complete the configuration by specifying the following fields:Basic settings
Advanced settings: Configuration
Advanced settings: Sampling
4. Obtain a Datafold API Key and CI config ID
Generate a new Datafold API Key and obtain the CI config ID from the CI API integration settings page: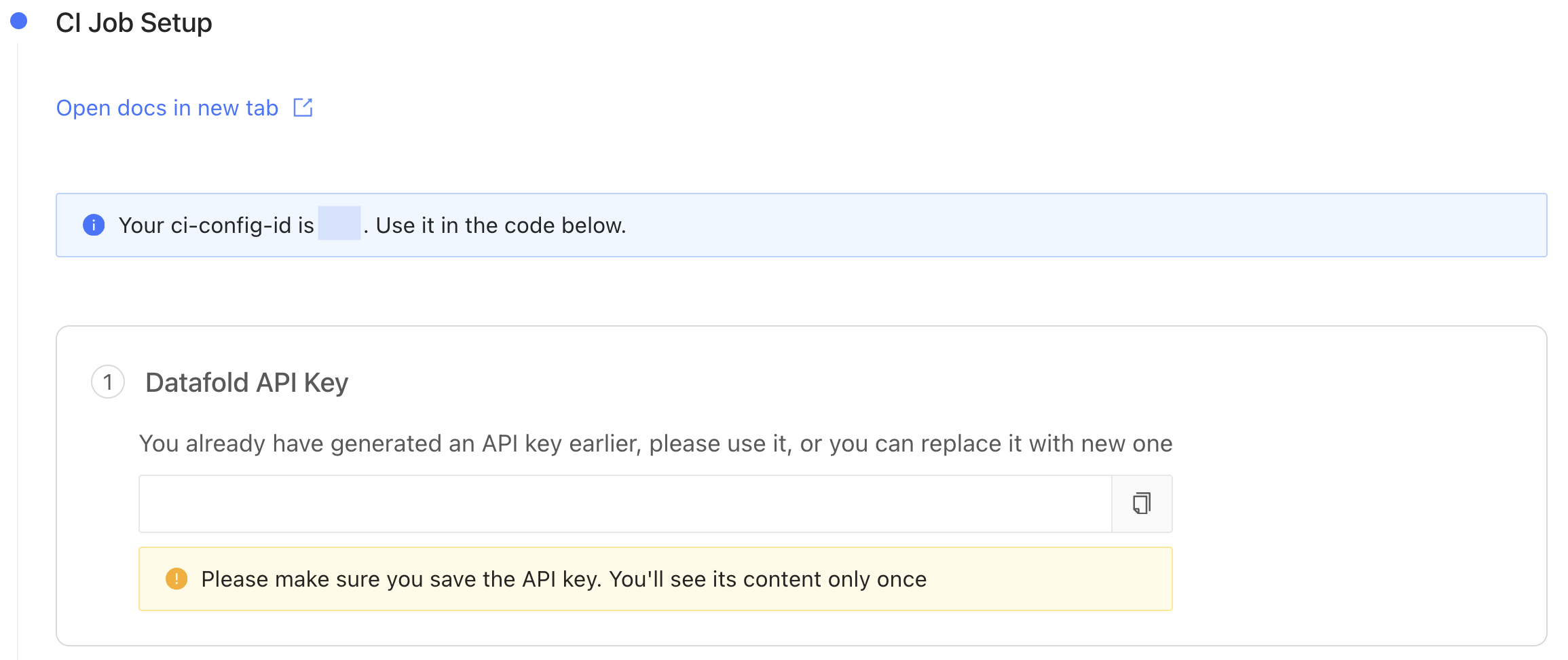
5. Install Datafold SDK into your Python environment
6. Configure your CI script(s) with the Datafold SDK
Using the Datafold SDK, configure your CI script(s) to use the Datafold SDKci submit command. The example below should be adapted to match your specific use-case.
json file format. Datafold can then determine which models to diff in a CI run based on the diffs.json you pass in to the Datafold SDK ci submit command.
JSON file is optional and you can also achieve the same effect by using standard input (stdin) as shown here. However, for brevity, we’ll use the JSON file approach in this example:
NOTEPopulating the
diffs.json file is specific to your use case and therefore out of scope for this guide. The only requirement is to adhere to the JSON schema structure explained above.CI Implementation Tools
We’ve created guides and templates for three popular CI tools. To add Datafold to your CI tool, adddatafold ci submit step in your PR CI job.
- GitHub Actions
- CircleCI
- GitLab CI
<datafold_ci_config_id> with the CI config ID value.NOTEIt is beyond the scope of this guide to provide guidance on generating the
<path_to_diffs_json_file>, as it heavily depends on your specific use case. However, ensure that the generated file adheres to the required schema outlined above.DATAFOLD_API_KEY in your GitHub repository settings.Once you’ve completed these steps, Datafold will run data diffs between production and development data on the next GitHub Actions CI run.Optional CI Configurations and Strategies
Skip Datafold in CI
To skip the Datafold step in CI, include the stringdatafold-skip-ci in the last commit message.