NoteThis section of the docs is only relevant if the data used as inputs during the PR build are inconsistent with the data used as inputs during the last production build. Please contact support@datafold.com if you’d like to learn more.
What is data drift in CI?
Datafold is used in CI to illuminate the impact of a pull request’s proposed code change by comparing two versions of the data and identifying differences. Data drift in CI happens when those data differences occur due to changes in upstream data sources—not because of proposed code changes. Data drift in CI adds “noise” to your CI testing analysis, making it tricky to tell if data differences are due to new code, or changes in the source data. Unless both versions rely on the same snapshot of upstream data, data drift can compromise your ability to see the true effect of the code changes.Why prevent data drift in CI?
By eliminating data drift entirely, you can be confident that any differences detected in CI are driven only by your code, not unexpected data changes. You can think of this as similar to a scientific experiment, where the control versus treatment groups ideally exist in identical baseline conditions, with the treatment as the only variable which would cause differential outcomes. In practice, many organizations do not completely eliminate data drift, and still derive value from automatic data diffing and analysis conducted by Datafold in CI, in spite of minor noise that does exist.Handling data drift
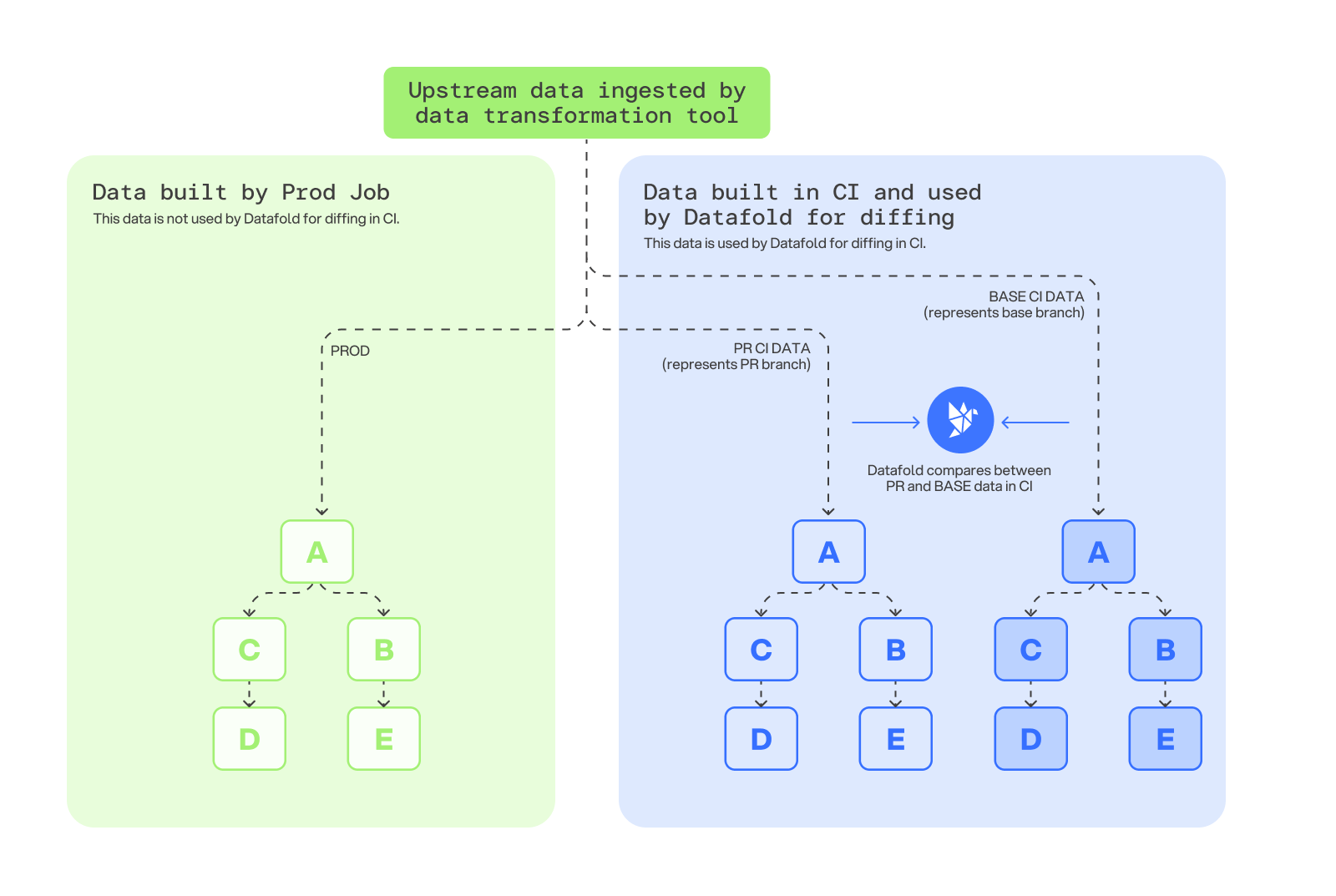
We recommend two options for removing data drift to the greatest extent possible: In both of these approaches, Datafold compares transformations of identical upstream data, so that any detected differences will be due to the code changes alone, ensuring an accurate comparison with no false positives. By building two versions of the data in CI, you can ensure an “apples-to-apples” comparison that depends on the same version of upstream data. When deciding between the two, choose the one that best matches your workflow:Build twice in CI
This method involves two CI builds: one representing PR data, and another representing production data, both based on an identical snapshot of upstream data.- Create a fixed snapshot of the upstream data that both builds will use.
- The CI pipeline executes two builds: one using the PR branch of code, and another using the base branch of code.
- Datafold compares these two data environments, both created in CI, and detects differences.
If performance is a concern, you can use a reduced or filtered upstream data set to speed up the CI process while still providing rich insight into the data.
This method assumes the production build doesn’t involve multiple jobs that process different sets of models at different times.
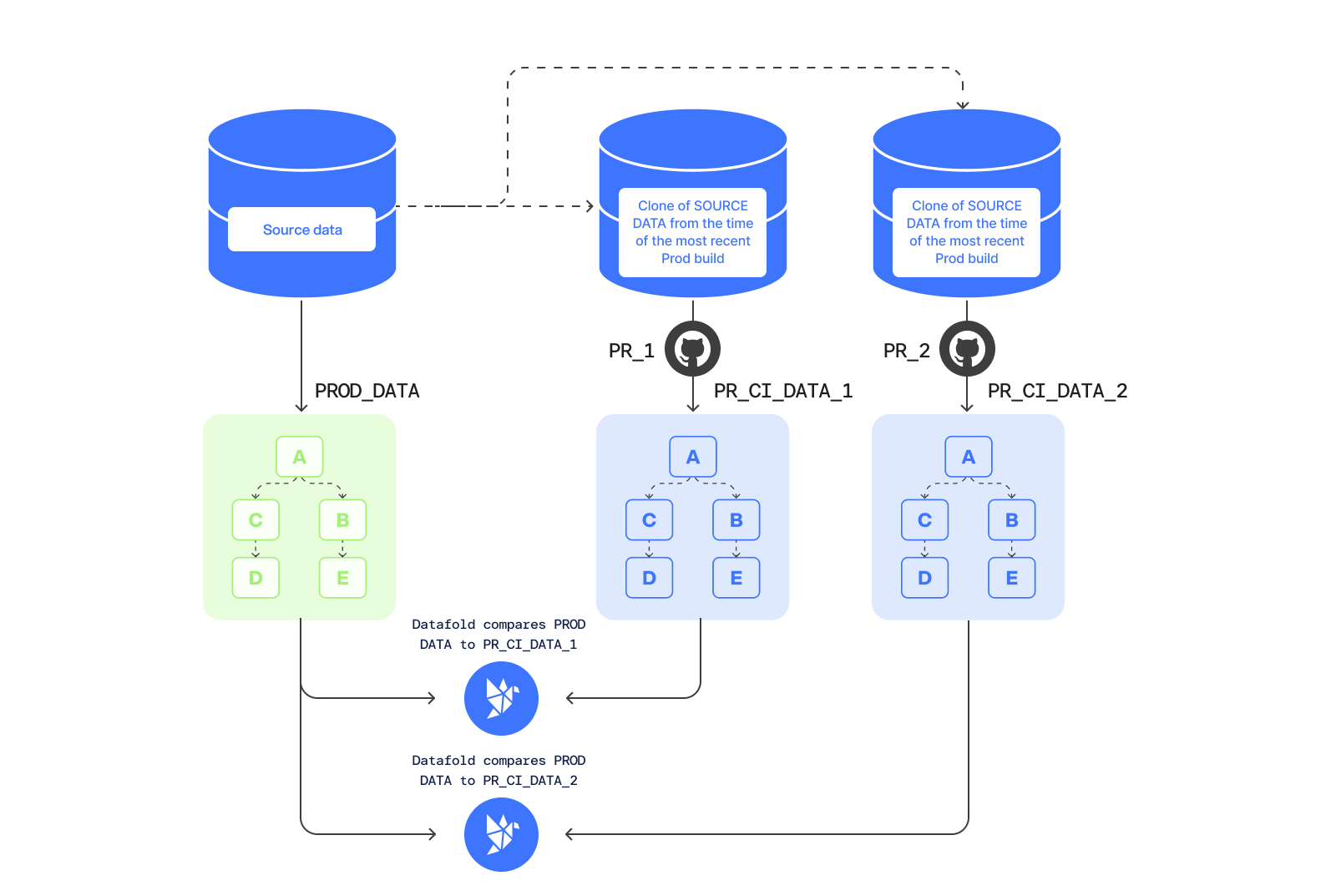
Build CI data from clone of prod sources
This method involves comparing a CI build based on a snapshot of the upstream source data from the time of the last production build to the production version of transformed data.- Update orchestration to create and store a snapshot of the upstream source data at the time of the production transformation job.
- The CI pipeline executes a data transformation build using the PR branch of code, with the snapshotted upstream data as the upstream source.
- Datafold compares the CI data environment with production data and detects differences.