Creating a new data diff
Source and Target datasets
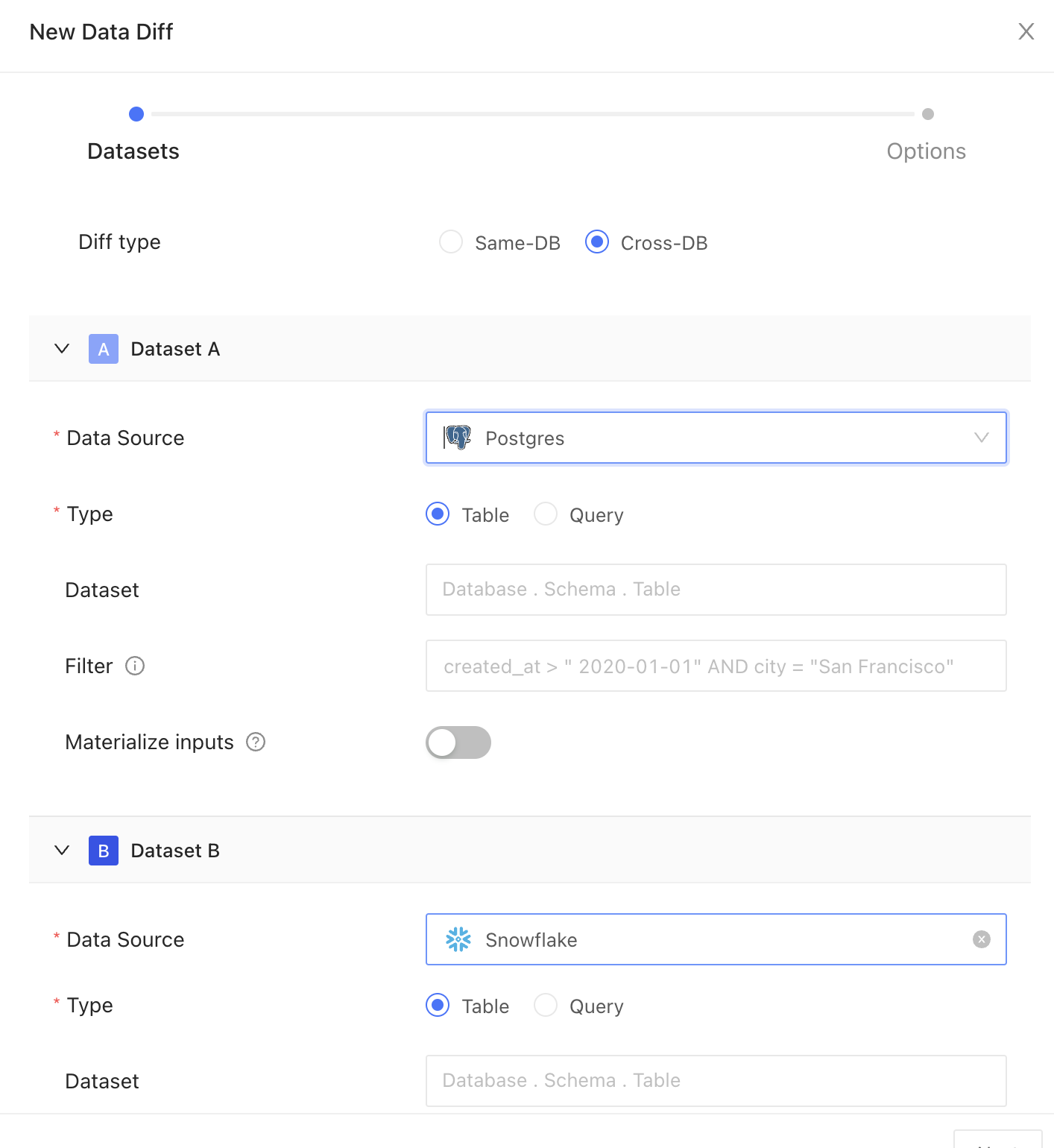
Data connection
Pick your data connection(s).Diff type
Choose how you want to compare your data:- Table: Select this to compare data directly from database tables
- Query: Use this to compare results from specific SQL queries
Dataset
Choose the dataset you want to compare. This can be a table or a view in your relational database.Filter
Insert your filter clause after the WHERE keyword to refine your dataset. For example:created_at > '2000-01-01' will only include data created after January 1, 2000.
Materialize inputs
Select this option to improve diffing speed when query is heavy on compute, or if filters are applied to non-indexed columns, or if primary keys are transformed using concatenation, coalesce, or another function.Column remapping
Designate columns with the same data type and different column names to be compared. Data Diff will surface differences under the column name used in the Source dataset.Datafold automatically handles differences in data types to ensure accurate comparisons. See our best practices below for how this is handled.
General
Primary key
The primary key is one or more columns used to uniquely identify a row in the dataset during diffing. The primary key (or keys) does not need to be formally defined in the database or elsewhere as it is used for unique row identification during diffing.Textual primary keys do not support values outside the set of characters
a-zA-Z0-9!"()*/^+-<>=. If these values exist, we recommend filtering them out before running the diff operation.Columns
Columns to compare
Specify which columns to compare between datasets. Note that this has performance implications when comparing a large number of columns, especially in wide tables with 30 or more columns. It is recommended to initially focus on comparisons using only the primary key or to select a limited subset of columns.Row sampling
Use sampling to compare a subset of your data instead of the entire dataset. This is best for diffing large datasets. Sampling can be configured to select a percentage of rows to compare, or to ensure differences are found to a chosen degree of statistical confidence.Sampling tolerance
Sampling tolerance defines the allowable margin of error for our estimate. It sets the acceptable percentage of rows with primary key errors (e.g., nulls, duplicates, or primary keys exclusive to one dataset) before disabling sampling. When sampling is enabled, not every row is examined, which introduces a probability of missing certain discrepancies. This threshold represents the level of difference we are willing to accept before considering the results unreliable and thereby disabling sampling. It essentially sets a limit on how much variance is tolerable in the sample compared to the complete dataset. Default: 0.001%Sampling confidence
Sampling confidence reflects our level of certainty that our sample accurately represents the entire dataset. It represents the minimum confidence level that the rate of primary key errors is below the threshold defined in sampling tolerance. To put it simply, a 95% confidence level with a 5% tolerance means we are 95% certain that the true value falls within 5% of our estimate. Default: 99%Sampling threshold
Sampling is automatically disabled when the total row count of the largest table in the comparison falls below a specified threshold value. This approach is adopted because, for smaller datasets, a complete dataset comparison is not only more feasible but also quicker and more efficient than sampling. Disabling sampling in these scenarios ensures comprehensive data coverage and provides more accurate insights, as it becomes practical to examine every row in the dataset without significant time or resource constraints.Sample size
This provides an estimated count of the total number of rows included in the combined sample from Datasets A and B, used for the diffing process. It’s important to note that this number is an estimate and can vary from the actual sample size due to several factors: The presence of duplicate primary keys in the datasets will likely increase this estimate, as it inflates the perceived uniqueness of rows.- Applying filters to the datasets tends to reduce the estimate, as it narrows down the data scope.
- The number of rows we sample is not fixed; instead, we use a statistical approach called the Poisson distribution. This involves picking rows randomly from an infinite pool of rows with uniform random sampling. Importantly, we don’t need to perform a full diff (compare every single row) to establish a baseline.
- Sampling tolerance: 5%
- Sampling confidence: 95%