Data Drift
Handling Data Drift with Datafold
One scenario where dbt Slim CI will not help eliminate data drift is when the modified model draws from frequently-updated raw sources (e.g., event data with 30 billion rows updated every 5 minutes). In that case, the upstream data is likely to change between the last Production and the current Staging runs, causing data drift.
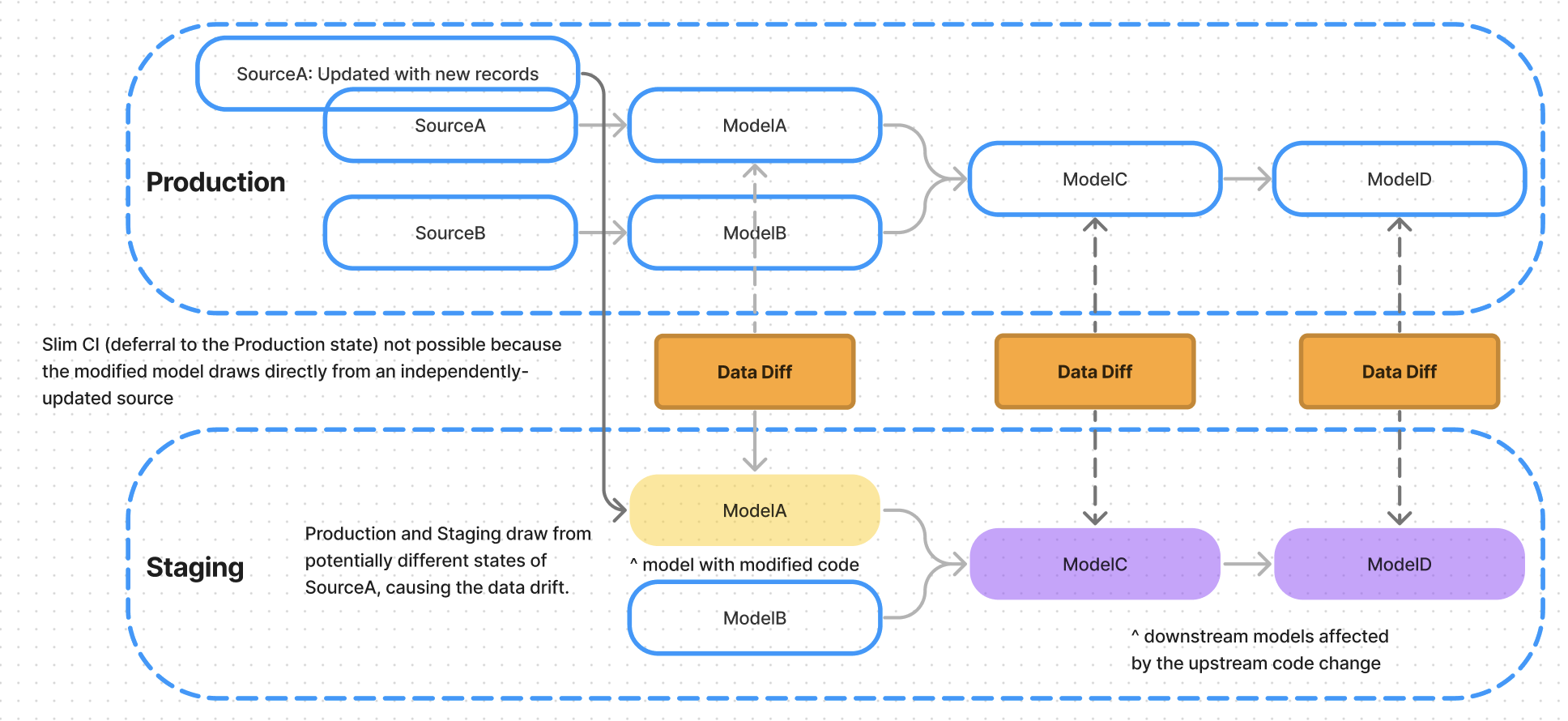
In this case, you can use Datafold to compare the data in the modified model to the data in the last Production run. This can be implemented in a few steps:
- Create copies of source data at the time of production runs
- Create macro (see code example below) that conditionally defers to these source copies during CI runs
Data drift is eliminated completely, with no ongoing manual effort needed after implementation
Workflow Example
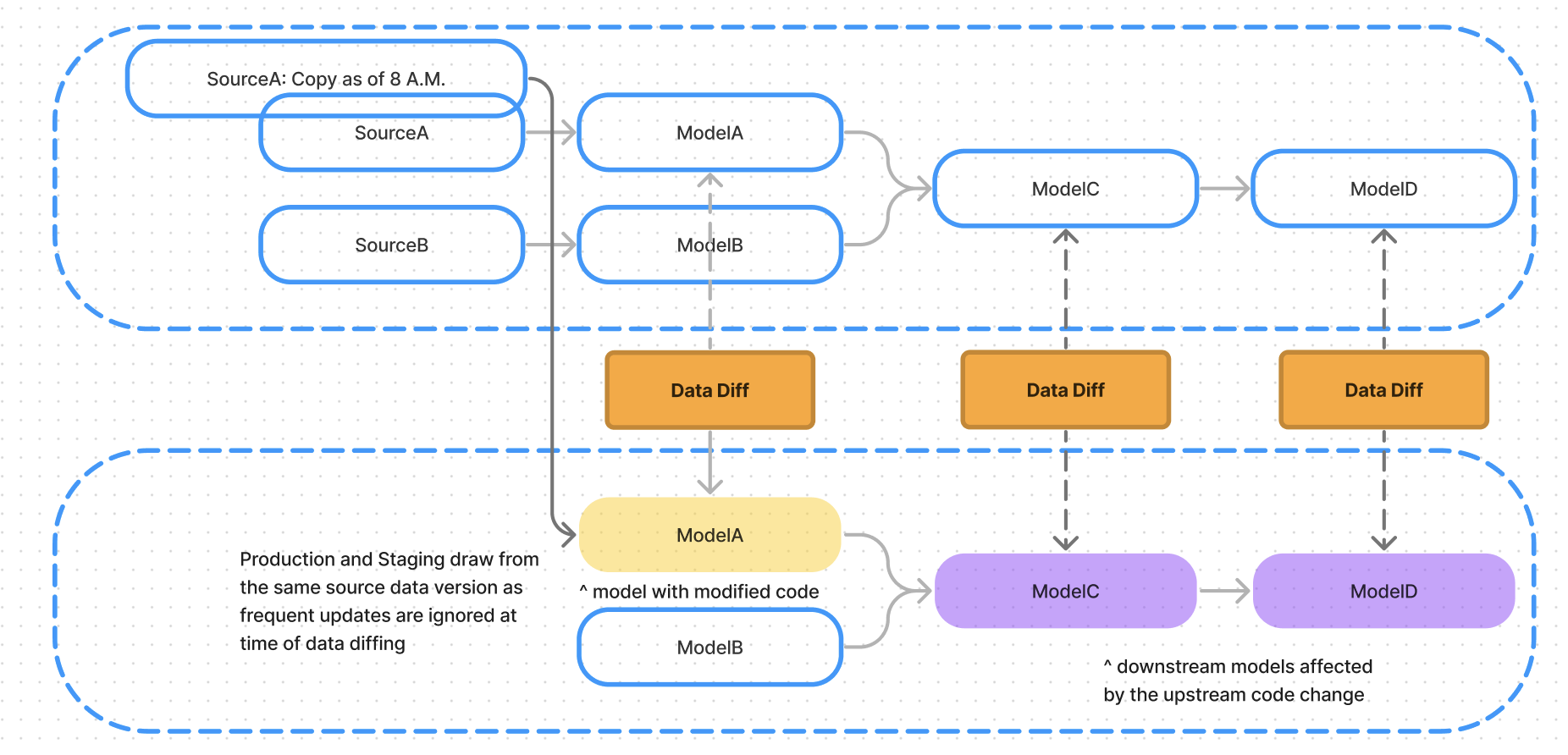
- Source Table A, with billions of records updated every 5 minutes, is referenced by dbt Model A, which is built in production every 2 hours.
- During every production job run, dbt Cloud creates a copy of Source Table A at that point in time (e.g., 8am): Source Table Copy A.
- In a dbt Cloud Slim CI run, dbt Model A references Source Table Copy A only during CI runs using a macro (see screenshot above).
- Macro logic: “Given that the target is CI, use the copy of Source Table A that was generated during the latest prod run as the upstream.”
- Then, Datafold will compare dbt Model A (prod) to dbt Model A (CI) with no difference in the upstream source data, because the Slim CI build references Source Table Copy A that was taken at the time of the last production run.
- All downstream data diffs will not have data drift as a result.
-- dbt_model_a.sql
select
*
{% if target.name == 'CI' %}
-- this can also be another source ref that's created by a post hook based on the original source
from {{ ref('source_copy_example') }}
{% else %}
from {{ source('web_events', 'page_views') }}
{% endif %}